
Continual Learning
Continual Learning/Incremental Learning/Lifelong Learning
目的:
Learn a sequence of contents one by one and behave as if they were observed simultaneously
Obtain strong generalizability to accommodate distributional differences within and between tasks
(获得强泛化能力以适应任务内和任务间的分布差异)
Ensure the resource efficiency of model updates, preferably close to learning only new training samples.
(保证模型更新的资源效率,最好接近只学习新的训练样本。)
Learn from dynamic data distributions.
困难:
catastrophic forgetting
trade-off between learning plasticity and memory stability
scenario complexity and task specificity
目前尝试的方法:
- adding regularization terms with reference to the old model (regularizationbased approach); 正则化
- approximating and recovering the old data distributions (replay-based approach); 基于回放
- explicitly manipulating the optimization programs (optimization-based approach); 基于优化
- learning robust and well-generalized representations (representation-based approach);
- constructing task-adaptive parameters with a properly-designed architecture (architecture-based approach).
Basic Formulation
不同分布的训练样本依次到达
以θ为参数的连续学习模型需要学习相应的任务( s ),没有或有限地访问旧的训练样本,并在其测试集上表现良好。
典型场景
- 实例增量学习( IIL):所有训练样本属于同一任务,分批到达。
- 领域增量学习( DIL ):任务具有相同的数据标签空间但不同的输入分布。不需要任务id。
- 任务增量学习(TIL ):任务具有不相交的数据标签空间。在训练和测试中都提供了任务标识。
- 类增量学习( CIL ):任务具有不相交的数据标签空间。任务身份只在训练中提供。
- 无任务连续学习( TFCL ):任务具有不相交的数据标签空间。无论是训练还是测试都没有提供任务身份。
- 在线连续学习( OCL ):任务具有不相交的数据标签空间。不同任务的训练样本以一次性数据流的形式到达。
- ·模糊边界连续学习( BBCL ):任务边界模糊,具有不同但重叠的数据标签空间。·
- 连续预训练( CPT ):预训练数据依次到达。目标是提高学习下游任务的绩效。
评估指标
- 迄今为止学习任务的整体表现
- 旧任务的记忆稳定性
- 新任务的学习可塑性。
Overall performance
总体性能通常通过平均精度( AA ) 和平均增量精度( AIA )来评估。
∈ [0, 1] denote the classification accuracy evaluated on the test set of the j-th task after incremental learning of the k-th task (j ≤ k).
Memory stability
Memory stability can be evaluated by forgetting measure (FM) and backward transfer (BWT)
FM at the k-th task is the average forgetting of all old tasks:
Learning plasticity
Learning plasticity can be evaluated by intransience measure (IM) and forward transfer (FWT)
IM is defined as the inability of a model to learn new tasks, which is calculated by the difference of a task between its joint training performance and continual learning performance:
where is the classification accuracy of a randomly initialized reference model jointly trained with for the k-th task. In comparison, FWT evaluates the average influence of all old tasks on the current k-th task:
是第j个任务用Dj训练的随机初始化参考模型的分类准确率
理论基础与分析
It is critical but extremely challenging to capture the distributions of both old and new tasks in a balanced manner
持续学习不仅需要在稳定性和可塑性之间取得适当的平衡,还需要足够的泛化能力来适应任务内部和任务之间的分布差异,其中寻找这样一个理想解的复杂度取决于参数空间的结构。
方法
Regularization-based Approach
选择性地正则化网络参数的变化,一种典型的实现方式是在损失函数中加入二次惩罚项,该惩罚项根据每个参数对执行旧任务的贡献或"重要性"来惩罚参数的变化
EWC
让模型参数受限地变动,阻碍在旧任务上重要参数的变化。比如,参数矩阵里面,某些参数对猫狗识别非常重要(这些重要参数在确定分类器分类猫狗的超平面过程中起主要作用),那么在训练狮虎识别时,记下这些参数原本的值,加一个损失函数阻碍它们的变化(参数像橡皮筋有弹性一样,想拉长它,会有弹力阻碍)
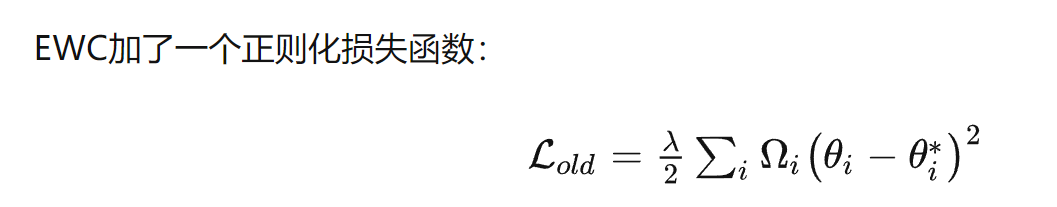

function regularization
LwF
蒸馏网络和微调

iCaRL
Incremental Classifier and Representation Learning
function regularization collaborates with replaying a few old training samples
三个要求
a) 当新的类别在不同时间出现,它都是可训练的
b) 任何时间都在已经学习过的所有类别中有很好的分类效果
c) 计算能力与内存应该随着类别数的增加固定或者缓慢增长
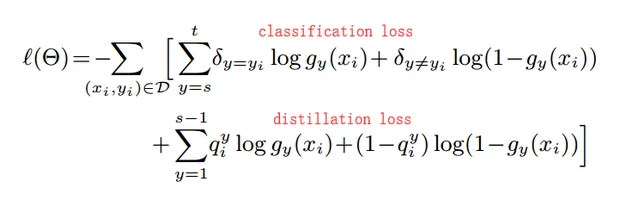
假设我们现在已经训练了s−1个类别的数据了,记为 ,因为通常内存资源有限,所以假设从每个旧数据类中选出一定数量的数据组成examplar sets,记为
然后现在又得到了t−s个新数据,记为,同理我们也需要提取出一部分数据,记为
有了新旧数据后,我们可以先将它们合并
然后就可以使用特征提取器φ(⋅)φ(·)计算每个类别的平均特征向量了。

iCaRL在训练新数据时仍然需要使用到旧数据,而LWF完全不用。所以这也就是为什么LWF表现没有iCaRL好的原因,因为随着新数据的不断加入,LWF逐渐忘记了之前的数据特征。
iCaRL提取特征的部分是固定的,只需要修改最后分类器的权重矩阵。而LWF是训练整个网络
在增量学习的设定中,每当特征提取器 改变时, 这个线性映射部分也是同步更新的,也就是说是耦合的。这是灾难性遗忘的原因
Replay-based Approach
该方向的特点是逼近和恢复旧的数据分布。典型的子方向包括经验回放,它将少量旧的训练样本保存在内存缓冲区中;生成重放,即训练一个生成模型来提供生成样本;特征重放,通过保存原型、保存统计信息或训练生成模型来恢复旧特征的分布。
维护特征级分布而不是数据级分布在效率和隐私方面有很多好处。
feature replay
Optimization-based Approach
通过显式地设计和操作优化程序来实现
GEM
并不需要保存之前的模型,只需要在模型参数更新后,之前任务的损失不增加就可以了。这可以通过计算梯度的夹角来确定
meta-learning
针对各种场景自动学习一种数据驱动的归纳偏差,而不是人工设计
ANML
该网络根据输入,通过另一个网络的激活来控制,从而导致第二个网络的选择性激活(这里也就是说有一个网络根据输入会输出一项0和正数组成的“门”,这个门作为一种激活函数处理我们分类网络的结果,从而使得部分权重被筛选)。这个随机门控取决于任务而不是数据本身。在训练中,我们不需要告诉网络他正在接受哪个任务的训练或测试,通过远远学习激活门。
Representation-based Approach
基于表征的方法
无/自监督学习(比传统的监督学习) 和大规模预训练(比随机初始化)已经被证明具有较少的灾难性遗忘。
归因于获得了更稳健的(如正交、稀疏、均匀散射等)表征
收敛到更宽的损失域
Architecture-based Approach
以往的工作一般将该方向分离为参数隔离和动态架构,这取决于网络架构是否固定。在这里,我们转而关注任务特定参数的实现方式,将上述概念扩展到参数分配、模型分解和模块化网络
通过迭代剪枝、激活值、不确定性估计等方法明确识别出当前任务的重要神经元或参数,然后将不重要的部分释放到下面的任务中。
些方法通常需要对参数使用进行稀疏性约束,并对冻结的旧参数进行选择性重用,这可能会影响每个任务的学习。为了缓解这种困境,如果网络架构的容量不足以很好地学习新任务,可以动态扩展网络架构
应用中的场景复杂性
Class-Incremental Learning
testing without providing task identities, which is more natural but also more challenging for classification tasks.
我们考虑两个二分类任务:( 1 ) “斑马"和"大象”;( 2 ) “兔子"和"知更鸟”。在学习完这两个任务后,TIL(Task Incremental Learning)需要知道它是哪个任务,然后对这两个类进行相应的分类,而CIL(Class Incremental Learning)则直接同时对这四个类进行分类。
Scarcity of Labeled Data
目前的持续学习设置大多假设增量任务有足够多的标记数据,而这些数据在实际应用中往往是昂贵且难以获得的。为此,越来越多的工作关注持续学习中标记数据的稀缺性。
构建用于知识蒸馏的样例关系图( ERL ),选择性地更新不重要的参数( FSLL )或稳定重要的参数( LCwoF ),协同快慢权重( MgSvF ),在损失图平坦区域内更新参数( F2M ),良好初始化的元学习( MetaFSCIL ),旧数据分布的生成式回放( ERDFR )
General Continual Learning
( General Continual Learning,GCL ) 是一个广泛的概念,描述了学习范式方面的潜在挑战,其中模型以在线方式观察增量数据,没有明确的任务边界
TASK SPECIFICITY IN APPLICATION
Object Detection
与视觉分类中每个训练样本只出现一个目标不同,目标检测中通常有多个属于新旧类的目标同时出现。这种共现对IOD提出了额外的挑战,在学习新类时,旧类被标记为背景(即, unannotated),从而加剧了灾难性遗忘。
Semantic Segmentation
( Continual Semantic Segmentation,CSS )旨在对类别进行像素级预测,并在旧类别的基础上学习新类别。与IOD类似,新旧类的对象可以一起出现。一些早期的工作在持续学习中使用新旧类的完整注释。然而,由于重新标注旧类的成本和时间消耗较大,更多的注意力集中在只使用新类的标注上,导致旧类被当作背景(称为背景位移),从而加剧灾难性遗忘。
Observation of Current Trend
以往的努力试图通过促进旧知识的记忆稳定性来解决这一问题。然而,最近的工作越来越关注促进学习可塑性和任务间可泛化性。
为促进记忆稳定性基础上的学习可塑性,涌现策略包括新旧任务解的重整化、新旧训练样本的均衡利用、为后续任务预留空间等
Cross-Directional Prospect
Diffusion Model
This provides a new target for continual learning of generative models, and its outstanding performance in conditional generation can facilitate the efficacy of generative replay
Neural Compression
A promising direction is to learn the mapping function of data compression adaptively from the distribution of incremental data, in order to obtain a better compression rate.一个很有前景的方向是从增量数据的分布中自适应地学习数据压缩的映射函数,以获得更好的压缩率。
Foundation Model
Increasing the scale of pre-training would facilitate knowledge transfer and mitigate catastrophic forgetting for downstream continual learning
增加预训练的规模可以促进知识迁移,缓解下游持续学习的灾难性遗忘.
Vision Transformer
需要专门的设计来克服灾难性遗忘,同时为在持续学习中保持任务特异性提供新的见解。
Embodied AI(具身智能)
通过与环境的交互来学习,不再从主要来自互联网的图像、视频或文本数据集学习。
The study of general continual learning helps the embodied agents to learn from an egocentric perception similar to humans, and provides a unique opportunity for researchers to pursue the essence of lifelong learning by observing the same person in a long time span
与神经科学的联系
生物神经网络能够灵活地调节突触可塑性以响应动态输入,包括( 1 )稳定先前学习的突触变化以克服随后的干扰,这激发了权重正则化策略来选择性地惩罚参数变化;( 2 )功能连接的数量扩展和修剪,为新的记忆形成提供灵活性,由此衍生出为学习当前任务创造额外空间并与前一个任务重新规范化的扩展-重整范式;( 3 )突触可塑性的活动依赖性和持续性调节,即元可塑性或"突触可塑性的可塑性" ;( 4 )兴奋神经元的抑制性突触,以减少其他神经元的活动
在区域合作方面,互补学习系统( Complementary Learning System,CLS )理论被广泛用于激发持续学习,将生物学习和记忆的优势归因于海马和新皮质的互补功能。海马负责快速获取特定经验的分离表征,而新皮质则能够渐进地获取用于泛化的结构化知识。
Conclusion
通过这篇综述性论文,我了解了持续学习的主要难点是灾难性遗忘(增量式学习任务会导致之前学习到的知识很快地被遗忘),核心就是要找到一种方法平衡记忆的稳定性和可塑性,最好能让它学到如何抓取新任务的特征并正确地分类,同时不影响之前在旧任务上的表现,熟悉了一些评价持续学习性能的指标,持续学习应用的场景。
目前的方法主要是正则化方式,知识蒸馏等方式,在参数更新的时候在尽可能保留之前学习到的特征;或重放的方式,设计代表性的样本集合,训练时用到部分之前的数据,或者使用参数孤立方法为每个任务分配了不同的模型参数。




